
Bạn có bao giờ tự hỏi làm thế nào các công cụ tìm kiếm như Google có thể biết về nội dung của hàng tỷ trang web trên internet? Câu trả lời nằm ở một công cụ quan trọng được gọi là crawl – quá trình tự động thu thập dữ liệu từ các trang web. Crawl trong tin học là gì? Với vai trò là chủ sở hữu website, tôi hiểu rõ tầm quan trọng của crawl. Nó giúp tôi và các chuyên gia tối ưu hóa công cụ tìm kiếm (SEO) hiểu rõ hơn cách các công cụ tìm kiếm hoạt động. Bằng cách tìm hiểu về crawl, tôi có thể nâng cao hiệu quả SEO, cải thiện khả năng hiển thị của website trên các kết quả tìm kiếm, và quản lý website của mình một cách hiệu quả hơn.
Web Crawler: Công cụ Thu thập Dữ liệu Trên Web
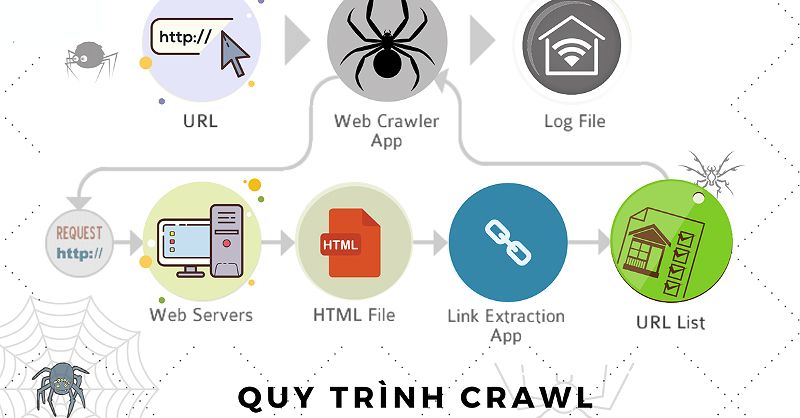
“Web crawler” là một phần mềm được thiết kế để tự động duyệt và thu thập thông tin từ các trang web trên internet. Nó hoạt động bằng cách bắt đầu từ một trang web cụ thể, sau đó theo dõi và truy cập các liên kết trên trang đó để tìm kiếm nội dung mới. Quá trình này được lặp đi lặp lại, cho đến khi web crawler đã thu thập được thông tin từ hàng triệu trang web.
Những ví dụ phổ biến về web crawler bao gồm Googlebot (của Google), Bingbot (của Bing) và Yandexbot (của Yandex). Mỗi web crawler này có nhiệm vụ thu thập và lập chỉ mục nội dung cho các công cụ tìm kiếm tương ứng.
Cơ chế hoạt động của web crawler bao gồm các bước sau:
-
Khởi đầu : Web crawler bắt đầu từ một danh sách các URL, thường được cung cấp bởi sitemap hoặc các trang web được thu thập trước đó.
 Khởi đầu
Khởi đầu -
Theo dõi liên kết : Web crawler sẽ theo dõi và truy cập các liên kết trên các trang web để tìm kiếm nội dung mới và các trang web liên quan.
 Theo dõi liên kết
Theo dõi liên kết -
Phân tích nội dung : Web crawler sẽ phân tích nội dung của trang web, bao gồm văn bản, hình ảnh, video và các yếu tố khác.
 Phân tích nội dung
Phân tích nội dung -
Lưu trữ dữ liệu: Sau khi thu thập được thông tin, web crawler sẽ lưu trữ dữ liệu vào cơ sở dữ liệu của công cụ tìm kiếm.
Crawl Budget: Ngân sách Thu thập Dữ liệu
“Crawl budget” là một khái niệm quan trọng liên quan đến hoạt động của web crawler. Nó đề cập đến lượng tài nguyên (ví dụ như băng thông, CPU) mà một công cụ tìm kiếm sẵn sàng dành cho việc thu thập dữ liệu từ một website cụ thể.
Các yếu tố ảnh hưởng đến crawl budget của một website bao gồm:
-
Kích thước website : Các website lớn thường có crawl budget thấp hơn so với các website nhỏ.
 Kích thước website
Kích thước website -
Chất lượng nội dung : Nội dung chất lượng cao, được tối ưu hóa cho SEO, sẽ thu hút nhiều crawl budget hơn.
 Chất lượng nội dung
Chất lượng nội dung -
Tốc độ tải trang : Website tải trang nhanh sẽ thu hút nhiều crawl budget hơn.
 Tốc độ tải trang
Tốc độ tải trang -
Số lượng backlink: Website có nhiều backlink chất lượng sẽ thu hút nhiều crawl budget hơn.
Để tối ưu hóa crawl budget của website, tôi đã áp dụng các chiến lược sau:
- Sử dụng sitemap: Tạo và gửi sitemap cho công cụ tìm kiếm để giúp web crawler dễ dàng tìm kiếm và thu thập dữ liệu.
- Tối ưu hóa robots.txt: Sử dụng robots.txt để chỉ định những trang web nào web crawler được phép thu thập dữ liệu.
- Cải thiện tốc độ tải trang: Nâng cao tốc độ tải trang để web crawler có thể thu thập dữ liệu hiệu quả hơn.
- Xây dựng backlink chất lượng: Tăng cường số lượng backlink chất lượng để thu hút nhiều crawl budget hơn.
Crawl Error: Lỗi Thu thập Dữ liệu
Trong quá trình thu thập dữ liệu, web crawler có thể gặp phải các lỗi sau:
-
Lỗi 404 : Trang web không tồn tại.
 Lỗi 404
Lỗi 404 -
Lỗi 500 : Lỗi máy chủ.
 Lỗi 500
Lỗi 500 -
Lỗi 301 : Chuyển hướng vĩnh viễn.
 Lỗi 301
Lỗi 301 -
Lỗi 302: Chuyển hướng tạm thời.
Để khắc phục các loại crawl error này, tôi đã:
- Sửa chữa các trang web bị lỗi 404.
- Kiểm tra và khắc phục lỗi máy chủ (lỗi 500).
- Đảm bảo các chuyển hướng (301, 302) được cài đặt chính xác.
Tôi cũng sử dụng các công cụ như Google Search Console và Screaming Frog SEO Spider để phát hiện và giải quyết các crawl error trên website của mình.
Vai trò của crawl trong tin học là gì trong SEO
Ngoài việc giúp các công cụ tìm kiếm biết về nội dung của website, “crawl” còn đóng vai trò quan trọng trong việc tối ưu hóa SEO. Khi web crawler thu thập thông tin từ website của tôi, nó sẽ giúp:
-
Đảm bảo website được hiển thị trên kết quả tìm kiếm: Khi web crawler lập chỉ mục nội dung của website, nó sẽ giúp đảm bảo rằng website của tôi được hiển thị trên trang kết quả tìm kiếm của Google, Bing hoặc Yandex.
-
Kiểm tra tính tương thích với tiêu chuẩn SEO: Thông qua quá trình thu thập dữ liệu, web crawler sẽ cung cấp thông tin về các yếu tố SEO như tiêu đề, nội dung, liên kết, v.v. Điều này giúp tôi kiểm tra và cải thiện tính tương thích của website với các tiêu chuẩn SEO.
-
Xác định thứ hạng trên kết quả tìm kiếm: Các web crawler như Googlebot, Bingbot hoặc Yandexbot được sử dụng để xác định thứ hạng của các trang web trên kết quả tìm kiếm. Hiểu rõ cách thức hoạt động của chúng sẽ giúp tôi cải thiện thứ hạng của website.
-
Theo dõi các thay đổi trên website: Khi web crawler cập nhật cơ sở dữ liệu của công cụ tìm kiếm về các thay đổi trên website, tôi có thể theo dõi và điều chỉnh các chiến lược SEO của mình.
FAQ
Câu hỏi 1: Crawl web có phải là một quá trình tự động hoàn toàn hay không? Phần lớn quá trình crawl web là tự động, tuy nhiên, các website chủ sở hữu như tôi có thể can thiệp vào một số khía cạnh của quá trình này, như sử dụng robots.txt để chỉ định những trang nào được phép crawl.
Câu hỏi 2: Làm sao để biết được website của mình đang nhận được bao nhiêu crawl budget? Tôi sử dụng các công cụ như Google Search Console để theo dõi và phân tích crawl budget của website. Các thông số như số lượng trang được crawl, tần suất crawl và các lỗi crawl sẽ giúp tôi ước tính crawl budget.
Câu hỏi 3: Crawl error có ảnh hưởng đến thứ hạng website trên công cụ tìm kiếm hay không? Có, crawl error có thể ảnh hưởng đến thứ hạng website trên công cụ tìm kiếm. Các lỗi như 404, 500 có thể khiến công cụ tìm kiếm đánh giá website của tôi là không chất lượng, từ đó ảnh hưởng đến thứ hạng.
Câu hỏi 4: Có nên sử dụng web crawler để thu thập dữ liệu từ website của đối thủ cạnh tranh hay không? Việc sử dụng web crawler để thu thập dữ liệu từ website của đối thủ cạnh tranh có thể gây ra các vấn đề về quyền riêng tư và bản quyền. Tôi không khuyến cáo bạn nên làm điều này. Thay vào đó, hãy tập trung vào việc cải thiện chất lượng nội dung và tối ưu hóa website của chính mình.
Kết luận
Trong bài viết này, tôi đã tìm hiểu về khái niệm “crawl trong tin học” và vai trò quan trọng của web crawler trong việc thu thập dữ liệu trên internet. Crawl là một quá trình tự động, được các công cụ tìm kiếm như Google, Bing và Yandex sử dụng để xây dựng cơ sở dữ liệu về các trang web.
Bằng cách hiểu rõ về crawl budget và cách khắc phục crawl error, tôi có thể tối ưu hóa website của mình để thu hút nhiều crawl budget hơn, cải thiện thứ hạng trên các kết quả tìm kiếm, và quản lý website một cách hiệu quả hơn. Ngoài ra, “crawl” còn đóng vai trò quan trọng trong các hoạt động SEO như đảm bảo website được hiển thị trên kết quả tìm kiếm, kiểm tra tính tương thích với tiêu chuẩn SEO, xác định thứ hạng và theo dõi các thay đổi trên website.
Tôi hy vọng rằng những kiến thức này sẽ giúp bạn nâng cao hiệu quả SEO và phát triển website của mình trong năm 2024 và những năm tiếp theo.


